
版本控件在任意都很重要软件开发环境机器学习中更是如此ML开发过程非常复杂包括大量数据 测试多模型 优化参数 调度特征
需要正确版本控制工具来管理和跟踪所有以上内容文章中,我们将探索机器学习中什么版本控制,你为什么需要它, 以及如何实现它
并读
变位控制是什么意思
版本控制过程跟踪和管理软件随时间变化无论是a或ML模型,你都需要跟踪软件团队成员所做的修改,修复错误并避免冲突。
实现此目标时,可使用版本控制框架开发框架跟踪每个提交者逐项修改并保存到特殊数据库中,供识别差异并帮助避免并发工作冲突并存
为何需要ML版本控制
机器学习开发过程包括许多迭代工作,开发者正在寻找最优性能模型同时修改超参数、代码和数据保存这些变化历史很重要 跟踪模型性能比参数, 省下时间再培训模型实验

机器学习版本控制分三部分:
- 代码解析
有建模代码 并有实现代码模型代码用于执行模型,执行代码用于推理两者都可用不同编程语言写出,
- 数据类
元数据 即数据模型信息并存实数据 数据集使用 训练运行模型元数据可以改变而数据不变,版本应连接数据到适当的元
- 模型化
模型连接所有以上参数和超参数使用模型版本控制系统后,可获取多项益益:
- 协作性 :如果你是单研究者 这可能无关紧要团队合作而项目复杂时,没有版本控制系统很难协作
- 版本化 :修改时模型可破解使用版本控制系统后,你能得到修改日志,当模型中断时会有所帮助,并可以恢复修改返回稳定版
- Reproducibility:取全机学习管道快照, 并允许重发相同输出, 即使是经过训练的权重, 省时再训练测试
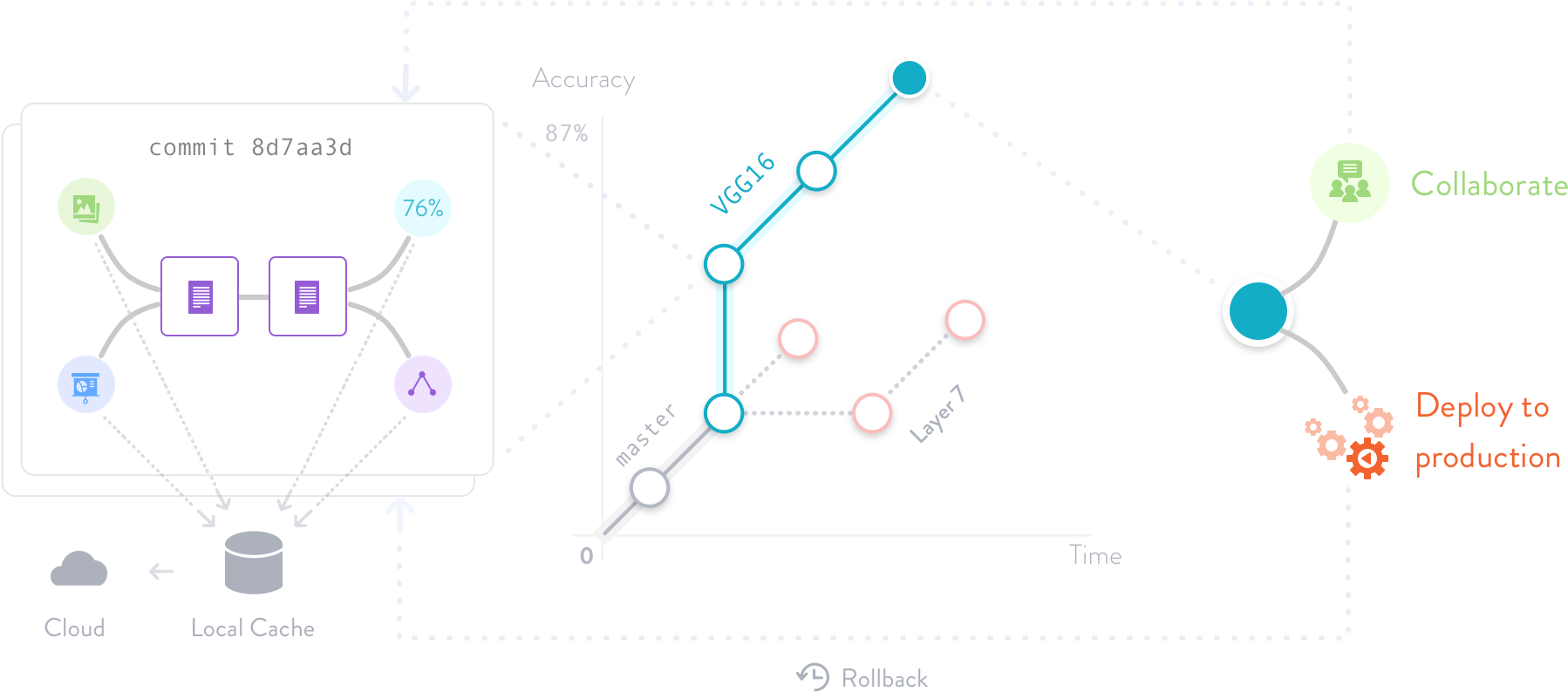
- 依赖跟踪 :跟踪不同版本的数据集评价开发模型超参数参数通过使用版本控制,您可以测试多模型不同分支或仓库,调和模型参数和超参数,并监控每项修改的精度。
- 模型更新模型开发不单步完成,循环工作有了版本控制帮助,你就可以控制哪个版本发布同时继续开发下一版
机器学习版本控制类型
ML版本控件有两种类型:
- 集中化版本控制系统
- 分布式版本控制系统
A级分布式版本控制系统版本控制系统 开发者计算机全机代码库 包括历史这使开发者能够合并并本地创建分支,完全不连接远程服务器或网络Git系统实例
使用此方法开发模型的长处是私自操作机器而无需上网和不依赖单服务器备份这有助于培训目的和项目小时使用开发者计算机上保留所有历史和分支数据需要大存储量, 正因如此才引入另一种集中版本控制法

A级集中版本控制系统化CVCS系统)版本控件开发者从包含所有文件与文件历史的单集中服务器检查存储器
系统很容易控制全代码库并存中心服务器连接问题可能慢化,加所有备份都存放在一个地方风险大
可当模型成熟并用作产品的一部分时使用此功能有不同的团队处理很多特征和变化, 不需要开发者计算机上所有代码, 并想降低合并和添加修改的复杂性
CVCS还减少了开发所需的存储规模,因为你将只有一个服务器包含所有代码修改,开发者只需要单版系统本地操作

模型版本控制
模型开发过程期间开发者遇到一些问题
- 高参数模型训练
- 上个模型训练后代码修改是什么
- 哪个数据集模型训练
- 上模型训练对依存性做了哪些修改
- 是什么变化使模型失效
- 是什么变化使模型表现更好
- 哪个版本模型上次发布
回答问题时,你需要跟踪模型开发期间的修改,这些修改提出了需要编译的内容问题。
ML开发中需要编译什么
回答问题取决于模型开发的哪一步let's see什么需要编译 在每个开发步骤
- 模型选择
第一,你需要决定使用哪种算法可能需要多算法比较性能所选算法应自定义版本,分别跟踪变化选择最优性能模型.
写模型或修改模型性能时,应跟踪变化以理解性能改变的原因
可使用不同的存储器实现每个模型以这种方式并行测试多模型并分解模型
- 模型训练
双参数训练用应跟踪可为每个超参数创建不同的分支以调和并跟踪模型性能每次超参数变化
训练参数应连同模型代码和超参数一起编译,以确保可复制相同的训练权值,甚至省回本版后再培训模型所需的时间
要用版本控制系统实现此功能, 需要为每个特征、 参数和超参数创建分支这使您能够使用一次修改执行分析并保持同模型相关全部修改并存到一个仓库中

- 模型评价
评估指开发者使用阻塞或测试集检查模型如何用它从未见的数据执行

屏蔽和性能结果应保留在版本系统上,并记录每步性能矩阵模型训练部分提到,选择最适配需要的参数后,需要合并成整合分支并运行此分支评价
- 模型验证
模型验证过程验证模型实数据性能如预期在此步骤中,你必须跟踪每项验证结果并跟踪模型生命周期期间性能模型变换增强模型性能比较不同模型时,应跟踪用于评价不同模型的验证矩阵执行此操作并评价整合分支性能后,模型验证可以在主分支上完成,在那里您可以合并评价修改,对它执行验证,并标签满足客户特征的修改为可部署版
- 模型部署
模型准备部署时,应记录哪个版本部署和每个版本的修改使您能够在主分支部署最新版本同时开发并改进模型时分阶段部署返回前工作版时使用模型失败时, 也会有故障容错性 。
最后,建模版可帮助ML工程师理解模型中哪些变化,研究者更新哪些功能,以及功能变化方式了解行为和方式会影响部署速度和简洁性,同时整合多重特征
如何实现模型版本控制
概述前一节提到的内容,实施模版控件的步骤如下:
- 创建单机库
- 单立分支查找模型参数、超参数或特征
- 创建整合分支,根据对每个特征分别性能分析收集需要的特征;
- 评估集成分支模型
- 从整合分支合并到主分支并实现验证
- 标签主分支版本数
机器学习模型版本控制工具
选择正确工具执行编译非常重要, 所选工具应提供管道每一部分清晰视觉, 并使用方法连接数据、 代码和模型编译等不同类型版本(而不仅仅是简单的管理跟踪文件修改)。
良好的模型编译系统将平滑团队成员之间的合作,为数据变换提供视觉化方法并实现开发过程自动化
海王星

开发用于研究生产,Neptune配有中枢,在那里你能找到方法帮助你处理机器学习管道生成元数据它可以记录、可视化、存储并比较元数据
可阅读更多如何在海王星建模检查站
DVC
开源版本控制系统,专为机器学习项目设计,为可复制和分享机器学习模型而建
比较工具
ML元数据
库存储模型元数据运行中生成的不同组件,包括训练模型及其执行初设计与Tensorflow合作,但可独立使用

摘要
版本开发期间和之后非常重要的一步通过多版本协作、历史保存和性能监控
工程中需要编译什么取决于当前开发过程的状态使用集中版本控制系统或分布式系统时,必须选择满足需求的适当工具。
引用 :
- https://www.tensorflow.org/tfx/guide/mlmd
- https://docs.www.musclechai.com/you-should-know/what-can-you-log-and-display#model-checkpoints
- https://flatironschool.com/blog/version-control-for-data-scientists
- //www.musclechai.com/blog/best-7-data-version-control-tools-that-improve-your-workflow-with-machine-learning-projects
- //www.musclechai.com/blog/version-control-guide-for-machine-learning-researchers
- https://medium.com/acing-ai/ml-ops-data-science-version-control-5935c49d1b76
- https://www.ibm.com/docs/en/udmh/9.1?topic=model-versioning-data-models
